본 글은 아래 강의를 참고하여 작성했습니다.
링크 참고: www.youtube.com/watch?v=_JB0AO7QxSA&list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv&index=7
오늘 공부할 주제
- Fancier optimization
- Regularization
- Transfer Learning
- 지난 강의를 다시 보면, 신경망의 가장 중요한 점은 최적화를 어떻게 하냐의 문제이다.
손실함수를 작성하고, 가중치에 각 값에 대해 손실 함수는 얼마나 좋은지 나쁜지에 대해 알려준다.
여기서 중요한 점은 최적화된 가중치를 찾아서 목표를 향해 가는 것이다. (좋은 학습을 위해 손실을 가장 줄여줄 가중치는 무엇인가)

저 3줄밖에 안되는 코드에 비교적 간단한 최적화 알고리즘(Vanilla Gradient Descent)에 안타깝게도 많은 문제들이 있다.
먼저, 문제점 1은

그래디언트 값을 계산하면 선이 지그재그처럼 앞뒤로 진행하게 된다. 즉, 그래디언트 방향이 정렬되지 않은 채 매우 느리게 움직임. 이러한 동작은 매우 바람직하지 않다.
하지만 이러한 문제는 high demension 에서는 흔하게 발생하는 상황이다.
왜냐하면 신경망은 수천 개, 수 억개로 매개변수로 이루어져있고, 방향 또한 수 만개, 수억개의 방향으로 뻗어간다.
각각마다 움직이는 방향이 다를 것이고, 가장 큰 것과 작은 것 사이의 비율차이가 상당히 크게 발생하기 때문에 이러한 상황에서 SGD는 그리 잘 수행되지 않을 것이다.
그리고, 또다른 문제점 2는,

정답은 SGD는 중단된다.
왜냐하면 저 지점에서는 Zero gradient를 갖게 되기 때문이다.
저 지점에서 SGD를 실행하면(SGD로 기울기를 계산하면) 저 지점 값이 0이기 때문에 어떠한 진전이 이루어지지 않는다. 즉, 우리는 local minima 에 빠져 갇히게 되는 것이다. 우리의 목표는 global minima 를 찾아야 하는 것을 명심하자.
local minima: 지역 최소값, saddle point: 안장점(gradient 가 0인 점에서 -,+로 gradient 가 서로 다른 부호를 가지는 점)
1차원으로만 보면 local minima 가 큰 문제처럼 보일 것이다.
그렇다면 local minima 가 일으키고 있는 방향에 대한 손실이 발생하게 되고, 이 값이 모든 방향에서 일어나고 있으니깐 loss function 이 고차원으로 갈수록 손실이 다 더해져서 그 값은 증가하게 될 것.
현재, 매우 큰 신경망을 학습시키고 있는데 여기서 문제는 local minima 가 아니라 바로 saddle point 이다.
loss function 이 고차원일수록 saddle points 가 많기 때문이다.
사실 saddle point 도 문제인데 saddle point 근처에도 문제가 있다.
두번째 목적 함수를 보면 saddel point 근처는 Zero Gradient 가 아니라 작은 경사로 이루어져 있다. 즉, 작은 그래디언트를 가지고 있어 느리게 진행되는 것이다. 이게 실제로 큰 문제래요,
이러한 문제점들을 해결해 줄 방법이 있다.
바로 Momentum 을 추가하는 것이다.

Gradient descent update 는 x의 위치를 직접 업데이트하는 것이였다면,
Momentum 은 속도를 업데이트 해주고, x 위치를 속도에 의해 업데이트 해주는 방식이다.
mu 는 마찰계수
Momentum 은 처음에 overshooting 이 일어나지만 Gradient descent 보다 점점 더 최소화에 빠르게 목표지점을 찾아간다.

SGD+Momentum 은 두 개의 방정식과 5줄의 코드가 추가되서 SGD보다 두 배 더 복잡하지만,
속도를 유지한다는 게 SGD+Momentum 의 가장 큰 포인트이다.
- 시간이 지날수록 그래디언트 방향으로 가는 게 아니라 속도에 기울기 추정치를 추가하여 그 다음 속도의 방향으로 이동한다.
즉, 현재 속도에 rho(마찰)라는 하이퍼 파라미터에 의한 그래디언트를 추가한다. 이로써 속도 벡터의 방향으로 이동하게 되는 것이다.

이러한 속도를 가지게 되면 이 속도와 함께 local minima 를 통과하게 되고, saddle point 까지 통과하여 내려가게 되는 것이다.

NAG(Nesterov Accelerated Gredient)라고도 한다.
Momentum 보다 conversion rate 가 좋다는 게 이론적으로 증명이 되어있고, 실제로도 그렇다.
Gradient 시작점은 Velocity 로 이동한 걸로 예상되는 지점부터 취하기 때문이다.

한글 강의 듣기~
왼쪽 식을 오른쪽 코드로 나타낸 것이다.
형태는 vanilla update 형태를 띄게 되고, 이는 momentum 이나 SGD 로 쉽게 바꿀 수 있어 보기좋은 형태로 우리가 만들 수 있다.
여기 또 다른 최적화 방법이 있다.
AdaGrad 알고리즘이다.

grad_squared(>0) 로 나눠주면서 파라미터를 계속 업데이트하기 때문에 이를 per-parameter adaptive learning rate method 라고 한다.
이는 모든 파라미터들이 동일한 learning rate 를 적용받는 것이 아니라 grad_squared 가 계속 제곱으로 building-up 이 되니까 파라미터 별로 다 다른 learning rate 를 영향을 받게 된다.
수직 축처럼 gradient 값이 큰 쪽은 x 의 업데이트 속도를 줄여주고, 수평은 gradient 값이 작은 쪽은 업데이트 속도를 빠르게 해줄 것이다. 이를 equalize 해줌으로써 경사에 경도되지 않게 해주는 것이다.?
이를 해결하기 위해 AdaGrad 를 약간 변형시킨 게 RMSProp 이다.
RMSProp 를 쓰는 이유
: AdaGrad 에서 학습을 계속 진행시키다보면 grad_squared 값이 계속 증가하게 될 것이고, 그러면 결국 step size 가 0에 매우 가까운 값이 될 것이다. 그렇게 되면 학습이 종료된다.
이를 방지하기 위해 움직일 수 있는 에너지를 줘야하는데 바로 RMSProp 를 쓰는 이유이다.
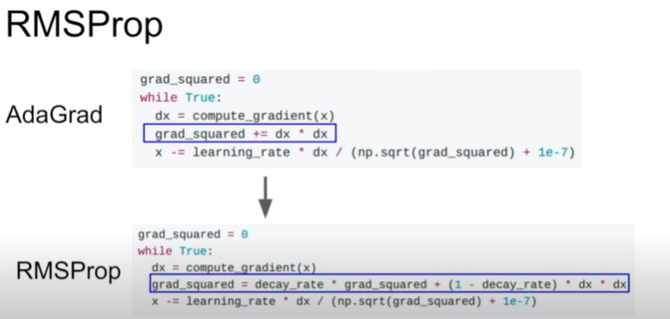
학습이 종료되지 않기 위해 바로 dacay_rate 하이퍼파라미터를 도입한다.
보통 decay_rate 는 0.9 아니면 0.99 로 설정해준다.
이로인해 grad_squared 값이 서서히 leaking 하는 것이다.
AdaGrad 의 장점인 경사에 경도되지 않은 효과 + AdaGrad 의 단점인 step size 가 0이 되면서 학습이 종료되는 것을 방지한 것,
다음으로 설명할 최적화 방법은 Momentum 과 AdaGrad / RMSProp 를 합친 Adam 알고리즘이다. (한글 강의는 RMSProp 와 유사한 것이라고 했다..)

하지만 여기서도 문제가 발생한다.
처음부터 크게 발을 내딛기 때문에 값이 이상한 방향으로 튈 수 있다는 점이다.

beta1 과 beta2 는 하이퍼파라미터인데 보통 0.9 나 0.99 로 설정한다.
Bias correction 는 최초의 first_moment 와 second_moment 가 0이 되었을 때 이를 scale-up 해준다.

정답은 없다.
그래서 초기에는 다소 큰 learning rate 를 설정하고, 서서히 일정한 간격으로 dacay 시키는 게 가장 최선이다.
무튼 최근엔 Adam 이 가장 많이 사용하는 최적의 알고리즘이랍니다. Adam 사용하세요.

1차 함수 근사치로 최소화하려는 과정
하지만 이 근사치는 유지될 수 없으며 매우 넓은 지역에서는 이를 수행할 수 없다.

~~~~~~~~~~~~~~~
hessaian 을 도입해서 경사뿐만아니라 곡면이 어떻게 구성되어있는지를 알 수 있다.
이를 알면 학습할 필요도 없이 바로 최저점으로 갈 수 있다. 그럼 learning rate 가 필요없게 된다.
하지만, 실생활에서 적용할 딥러닝에는 부적합니다.
hessaian 행렬은 N x N 행렬이기 때문에 엄청난 큰 행렬이고, N 이 1억개라고 가정한다면 연산 메모리에 저장할 수 없을 정도로 너무 크다.
그럼에도 불구하고 사용하고 싶어서 나온 방법이,
BFGS 는 hessaian 을 역행렬하는 대신에 보통 낮은 순위 근사값을 사용함으로써 연산을 줄여주는 것이다. 하지만 여전히 메모리에 저장하기 힘들어서 큰 네트워크에서 사용이 불가능하다.
L-BFGS(메모리에 저장하지 않음) 가 가끔 사용되긴 한다.
기본적으로 무거운 함수이기 때문에 모든 곳의 noise 들을 제거하고 사용해야 한다. 미니배치(우리가 자주 사용하는)에는 부적합.
너무 어려우니 더 이상 깊게 설명하지 않겠다.
결론! Adam이 다양한 신경망학습에 가장 좋은 알고리즘이며, 만약 니가 full batch를 업데이트할 여유가 있다면 L-BFGS를 사용하면 된다.
다만, L-BFGS 는 모든 noise 들을 제거해야 하기 때문에 실제로도 학습에 적합하지 않다.
지금까지 Training error(훈련 오류)를 줄이고 최적화하는 방법에 대해 설명했다.
하지만 우리는 보이지 않는 많은 데이터들 간의 Training error 에 대해 잘 신경쓰지 않는다.
우리는 train 과 test 의 간격 차이를 줄이는 방법에 대해 관심이 있을 뿐이다.
가장 빠르고 쉬운 방법은 Model Ensembles 이다.
하지만 이건 일시적인 개선 방법일 뿐이다.
우린 단일 모델의 성능 향상을 원한다.
그 방법이 바로 정규화, Regularizaion 이다.

앞으로 통과할 때 일부 뉴런을 임의로 0을 설정하면서 하위 집합을 만든다.
이 과정은 한 번 통과할 때마다 한 레이어씩 진행되는데
한 레이어를 통과할 때 그 레이어 값을 무작위로 일부를 0으로 설정하는 것이다.
즉, 우리는 뉴런의 일부 집합만 사용하게 된다. (각 반복 과 정마다 매번 다른 뉴런 부분 집합을 사용한다.)

Dropout 은 과적합을 방지하는 데에 도움을 준다.
그리고 단일 모델을 모델 앙상블을 하는 것과 비슷하게 만든다.
가중치들을 공유하는 하나의 모델로 생각하게 되는 것이다.
여러개의 모델의 파라미터를 평균내서 앙상블의 효과를 냈다라고 해석될 수 있다.
test time 때는 Dropout 사용 안한다.

test time 은 무작위성을 갖는 것이 나쁠 수 있다.
모든 뉴런이 살아있어야 좋은 결과 값을 얻을 수 있기 때문이다.

test time 때는 각 뉴런에 activate 값들을 training time 만큼 scaling 을 해줘야 한다.
training time 계산할 때 test time의 결국 1/2배(=p)가 됨.
그래서 p 를 각각 곱해줌.

training time 때 p 를 나눠서 scaling 을 미리 처리해준다. 이 방법이 보다 일반적인 방법
Dropout 말고도 정규화를 위해 다른 방법들도 있다.
- Batch Normalizaion : 일반적으로 많이 사용함.
- Data Augmentation : 수평/수직 반전, random crop/scale, colo jitter(밝기/대조) 등
- DropConnect: 활성화를 0으로 만들어 노드를 아예 탈락시키는 게 아니라 가중치를 0으로 설정해 노드를 부분적으로 활성화시킬 수 있다.
- Fractional Max Pooling
- Stochastic Depth
Transfer Learning
(자막 안나오는거 실화니...)
A를 학습시키고 싶은데 데이터 셋이 너무 작을 때 사전에 학습된 모델(pre-trained model)을 불러와 사용하는 것.
'CS231n 공부하기' 카테고리의 다른 글
| Lecture 13 | Generative Models (1) | 2021.01.12 |
|---|---|
| Lecture 4 | Backpropagation and NN part 1 (0) | 2020.10.20 |
| Lecture 3 | Loss fn, optimization (0) | 2020.10.19 |
| Lecture 2 | Image Classification (0) | 2020.10.13 |




댓글