안녕하세요 고공입니다:)
실무에서 SQL를 많이 사용하는데 그때그때 알고 넘어가기엔 나중에 잊어버릴 것 같아서 정리를 해야 겠다는 생각이 들었습니다. 그래서 이번 시간은 해당 책을 참조해 SQL의 인덱스에 대해 정리를 해보려고 합니다.
실무에서 사용되는 데이터베이스는 굉장히 많은 데이터가 있고, 용량조차도 큰 데이터베이스에서 정보를 추출할 경우 많은 시간이 소요된다는 것은 다들 알고 계실 겁니다. 이러한 문제점을 해결해 주는게 바로 인덱스입니다.

그렇다면 인덱스에 대해 더 자세히 알아볼까요?
인덱스는 SELECT를 사용해서 테이블을 조회할 때 결과를 빠르게 추출하도록 도와주는 기능입니다. 실무에서는 현실적으로 인덱스 없이 데이터베이스 운영이 불가능할 정도로 인덱스는 데이터를 빠르게 찾을 수 있도록 도와주는 도구입니다.
- 인덱스의 개념
- 인덱스의 장단점
- 인덱스 종류
- 정리
순으로 빠르게 살펴보겠습니다.
인덱스의 개념
저희는 지금 동물 사전를 가지고 있다고 가정합시다. 만약 10000페이지가 넘는 사전에서 개구리에 대해 찾아보고 싶다면 어떻게 해야 할까요.
동물 사전의 맨 뒷쪽에는 바로 '찾아보기'라는 장이 있습니다. 찾아보기는 ABC 또는 가나다 순으로 정렬되어 본인이 알고 싶은 단어나 정보가 쪽수와 함께 적혀져 있습니다. 그래서 개구리를 찾아보고 싶다면 ㄱ부분을 찾아서 쉽게 개구리 단어를 찾을 수 있고, 페이지 번호가 적혀 있어 빠르게 이동할 수 있습니다.
하지만 찾아보기가 없는 책들도 있겠죠. 이럴 경우는 어떻게 해야 할까요. 책을 처음부터 일일이 확인해볼 수 밖에 없습니다. 한번에 찾거나 첫 부분에 나오길 기도하며 운이 좋길 기다려야죠.
우리는 운에 기댈 수 없습니다. 위에서 언제 다 하냐고 계속 쪼기 때문이죠. 우리의 정신 건강에도 좋지 않습니다.
그래서 SQL에 인덱스가 있는 이유입니다.
사실 데이터를 찾을 때, 인덱스의 사용 여부에 따른 결과값의 차이는 없습니다. 즉, 책의 찾아보기가 없다고 글자를 못찾는 것은 아닙니다. 단지 시간이 오래 걸릴 뿐이죠.
실무에서 운영하는 테이블에는 인덱스의 사용 여부에 따라 성능 차이가 날 수 있습니다. 대용량의 테이블의 경우 더욱 그러합니다.
인덱스의 장단점
인덱스의 장점은 다음과 같습니다.
- SELECT 문으로 검사하는 속도가 매우 빠르다.
- 그 결과 컴퓨터의 부담이 줄어들어서 전체 시스템의 성능이 향상된다.
인덱스는 단점은 다음과 같습니다.
- 인덱스도 공간을 차지해서 추가적인 공간이 필요하다. (대략 테이블 크기의 10% 추가 공간 필요)
- 인덱스를 만드는 데 시간이 오래 걸릴 수 있다.
- 데이터의 변경작업(INSERT, UPDATE, DELETE)이 자주 일어나면 오히려 성능이 나빠질 수 있다.
인덱스를 사용할 때 주의할 점
인덱스를 제대로 이해하지 못한 채 좋다고 남용하는 것은 위험합니다. 영양제가 몸에 좋다고 하루에 100알씩 먹는 것은 안좋겠죠. 적당한 양을 먹어야 몸에 좋은 것이지 좋다고 하루에 100알씩 먹는 것은 오히려 몸에 해로울 수 있습니다.
우선 예를 들어서 이해보도록 하겠습니다.
SQL 책을 공부하고 있다고 가정해봅시다. 그중 SELECT 라는 단어를 찾아보려고 합니다. 찾아보기에는 SELECT 단어에 대한 안내가 있을 겁니다. 아마도 SELCET는 책의 여러 페이지에서 언급될 것이고, SELECT 단어 자체에도 여러 페이지에서 언급될 것입니다. 그러면 많은 페이지가 표기되겠죠.
그렇다면 찾아보기를 통해 본문에 있는 SELECT를 찾아보겠습니다. 찾아보기 한 번, 본문 한 번, 찾아보기 한 번, 본문 한 번,,, 계속 찾아보기와 본문을 왔다 갔다 하게 될 것입니다. 번거롭긴.. 하네요. 차라리 처음부터 넘기면서 찾아보는 게 덜 귀찮을 것 같습니다.
이렇게 찾아보기에 만들지 않아도 될 단어들이 쌓이면 책의 두께만 두꺼워지고, 찾아보기를 사용했는데도 오히려 더 오래 걸릴 수도 있습니다.
실무에서도 비슷한 일이 발생할 겁니다. 필요 없는 인데스를 만드는 바람에 차지하는 공간만 더 늘어나고, 인덱스를 사용하는 것이 전체 테이블을 찾아보는 것보다 느려질 수 있습니다.
인덱스가 있다고 무조건 좋은 것은 아니라고 말씀드리고 싶었습니다.
인덱스의 종류
드디어 제가 이 글을 쓰는 이유가 나왔네요. 인덱스의 종류인 클러스터형 인덱스와 보조 인덱스에 대해 알아보겠습니다.
인덱스에는 클러스터형 인덱스와 보조 인덱스가 있습니다. 클러스터형 인덱스는 영어사전과 같고, 보조 인덱스는 책의 뒤에 찾아보기가 있는 책과 같습니다.
클러스터형 인덱스(Clustered Index)는 기본 키로 지정하면 자동 생성되며 테이블에 1개만 만들 수 있습니다. 이때, 기본 키로 지정한 열을 기준으로 자동 정렬됩니다. 영어사전처럼 이미 알파벳 순서대로 정렬되어 있는 것입니다. 그래서 별도의 찾아보기가 없습니다. 책 자체가 찾아보기니까요.
보조 인덱스(Secondary Index)는 고유 키로 지정하면 자동 생성되며 여러 개를 만들 수도 있고, 자동 정렬되지는 않습니다.
이제 테이블에 적용되는 인덱스를 살펴보겠습니다.
인덱스는 테이블의 컬럼 단위에 생성되며, 하나의 열에 하나의 인덱스를 생성할 수 있습니다.
클러스터형 인덱스
위에 보이는 member 테이블은 mem_id(회원 아이디)를 기본 키로 정의해 생성했습니다. 이렇게 기본 키로 지정하면 자동으로 mem_id 열에 클러스터형 인덱스가 생성됩니다.
기본 키는 테이블에 하나만 지정할 수 있기 때문에 결국 클러스터형 인덱스도 테이블에 한 개만 만들 수 있습니다.

SHOW INDEX 문을 사용하면 인덱스 정보를 확인할 수 있는데 Key_name 부분을 보면 primary라고 써있습니다. 이것은 기본 키로 설정해서 '자동으로 생성된 인덱스'라는 뜻입니다. 이게 바로 클러스터형 인덱스입니다.
그리고 Column_name이 mem_id로 설정되어 있다는 것을 mem_id 열에 인덱스가 만들어져 있다는 말입니다.
Non_Unique는 '고유하지 않다'라는 뜻으로 중복이 허용되냐는 것입니다. 0이라는 것은 False로 이 인덱스는 중복이 허용되지 않는 인덱스 입니다.
클러스터형 인덱스의 특징
클러스터형 인덱스의 특징은 아래의 그림과 같이 자동으로 정렬된다는 것입니다.
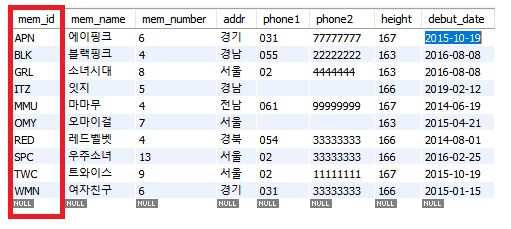
이렇게 클러스터형 인덱스가 생성된 열은 데이터가 자동 정렬됩니다.
보조 인덱스
보조 인덱스는 단순 보조 인덱스와 고유 보조 인덱스로 나뉩니다.
이 둘의 차이점은 중복을 허용하냐의 차이인데 중복을 허용하는 것은 단순 보조 인덱스이고, 그렇지 않은 것은 고유 보조 인덱스 입니다.
이 둘은 제약조건인 UNIQUE의 사용 여부에 따라 나뉠 수 있습니다.

위에 보는 것처럼 Key_name에 열 이름이 써 있는 것은 보조 인덱스라고 보면 됩니다. mem_name 열은 UNIQUE를 지정했고, addr 열은 지정하지 않았습니다.
그렇다면 mem_name은 고유 인덱스이고, addr는 단순 인덱스라고 볼 수 있겠군요.
보조 인덱스의 특징
보조 인덱스의 특징은 클러스터형 인덱스와 달리 자동으로 정렬되지 않는다는 것입니다.
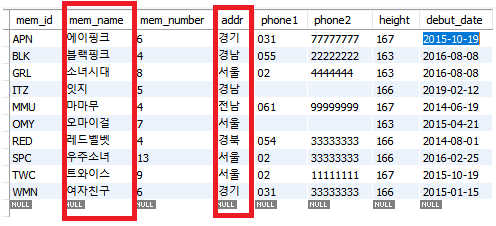
위의 테이블를 봐도 순서나 내용이 바뀌지 않습니다. 보조 인덱스는 테이블에 여러 개를 설정할 수 있습니다. 하지만 보조 인덱스를 만들 때마다 그만큼 공간을 차지하게 되고, 전반적으로 시스템에 좋지 않는 영향을 끼치게 됩니다. 그러므로 꼭 필요한 열에만 적절한 보조 인덱스를 생성하는 것이 좋습니다.
정리
| 클러스터형 인덱스 | 보조 인덱스 | |
| 영문 | Clustered Index | Secondary Index |
| 관련 제약조건 | 기본키(Primary Key) | 고유키(Unique) |
| 테이블당 개수 | 1개 | 여러 개 |
| 정렬 | O | X |
| 비유 | 영어사전 | 책의 찾아보기 |
클러스터형과 보조 인덱스을 직접 생성,제거하는 실습을 보고 싶은 경우 이 글을 읽어주세요.
오늘도 저의 글을 읽어주셔서 감사합니다!
'데이터분석 공부하기' 카테고리의 다른 글
| ERD 그릴 때 주의해야 할 사항 (0) | 2022.10.02 |
|---|---|
| 선형판별분석 LDA 이해하기 (0) | 2022.09.18 |
| 로지스틱 회귀 (0) | 2022.03.21 |
| 다항 회귀 (0) | 2022.03.17 |
| 선형 회귀 (0) | 2022.03.17 |



댓글