안녕하세요 고공입니다.
오늘부터 10월이 시작됐으니까 저번 글에 보신 분들은 아마 아실 수도 있을 거라고 생각합니다. 제가 어제부로 한 프로젝트가 끝났습니다!! 와아아아 🙌
사실 너무 기뻐요. 프로젝트하는동안 야근도 정말 많이 했고, 주말출근도 많이 했어서 기억에 남을 프로젝트가 될 것 같습니다. 그리고 DB도 직접 다뤄보고 설계도 발가락 살짝 담가보니까 아직도 제가 알아야 할 영역들이 많이 남아있어서 공부를 더더더 많이 해야겠다는 생각도 했습니다. 이번 프로젝트 기간 끝자락에서 ERWIN 프로그램을 이용해서 ERD를 많이 다뤄봤는데요, 써보면서 주의해야 할 점이나 공부했던 점을 이번 글을 통해 간단히 살펴볼 계획입니다.
1. 기본키 선정
제가 해야 했던 일 중 하나는 기존의 테이블들을 합쳐 하나의 데이터 셋으로 만드는 일이였습니다. 그렇다면 여러 개의 테이블을 이용해 하나의 데이터 셋을 만들 때 기본키를 새로 설정해줘야 합니다.
일단 기본키의 대표적인 성질은 다음과 같습니다.
- 고유값을 가져야 한다.
- NULL은 허용하지 않는다.
업무를 진행할 때 이 기본 성질을 잘 숙지하고 있어야 합니다.
가장 베스트는 기존의 테이블들의 기본키를 이용하는 것입니다. 기존에 있는 키들을 사용하기 때문에 ERD 상에 관계를 표시할 때도 편하고, 새로운 컬럼을 만들 필요도 없기 때문입니다. 대부분 기존의 있는 기본키를 사용했지만 이들로 도저히 안 되는 경우가 있습니다.
바로 기본키가 너무 많을 경우입니다.
예를 들어 생산, 수출, 수입 테이블이 있다고 가정합시다.
저희는 세 개의 테이블을 공급실적 테이블인 하나의 테이블로 합치고 싶습니다.
편의를 위해 기본키만 표시해뒀습니다.
생산 테이블은 기본키로 업소순번, 공장번호, 생산연도, 생산월, 생산실적관리번호를 가지고 있고,
수출 테이블은 업소순번, 공장번호, 수출연도, 수출월, 수출실적관리번호를 가지고 있고,
수입 테이블은 업소순번, 공장번호, 수입연도, 수입월, 수입실적관리번호를 가지고 있습니다.
이 세 테이블은 업소순번, 공장번호는 공통으로 가지고 있군요.
그렇다면 이 세 테이블을 합쳤을 때 하나의 테이블은 어떤 기본키를 가져야 할까요?

이럴 때 공통으로 가지는 업소순번, 공장번호를 기본키로 사용하고, 새로운 키를 하나 생성해주는 것이 좋습니다.
그렇지 않으면 생산연도에서 수입실적관리번호까지 총 9개를 추가로 사용해야 하는데 그럼 기본키가 11개나 됩니다.
DB 입장에서 보면 별로 효율적이지 못합니다.
그래서 실적관리번호라는 새로운 키를 하나 생성하여 이 공급실적 테이블은 업소순번, 공장번호, 실적관리번호를 기본키로 가질 수 있습니다.
그러면 기본키 3개로 끝낼 수 있겠죠?!
2. 부모 테이블과 자식 테이블의 설정
먼저 ERD의 규칙을 살펴보면 다음과 같습니다.
여기서 '~로 구성되어 있다'는 말을 쉽게 설명하면 '~를 포함하고 있다'라고 생각하시면 됩니다. 이 말은 A는 B를 포함하고 있다는 말인 거죠.
그렇다면 ERD를 그릴 때 테이블 간 부모와 자식의 관계를 알아야 그릴 수 있습니다.
예를 들어 아래의 그림처럼 A 테이블의 기본키를 B 테이블이 가지고 있다면 A 테이블은 부모 테이블, B 테이블은 자식 테이블을 뜻합니다.
또한, 점선과 실선으로 관계를 구분할 수 있는데 위 그림처럼 자식 테이블이 부모 테이블의 기본키를 가지고 있으면서 기본키로 사용하는 경우엔 실선으로 표현하고,
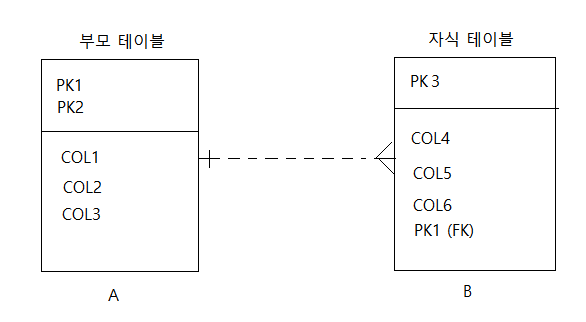
위 그림처럼 자식 테이블이 부모 테이블의 기본키를 가지고 있지만 기본키로 사용하지 않을 경우엔 점선으로 표현합니다.
ERWIN은 일단 테이블을 만들고 관계선을 표시하기 때문에 자동으로 실선, 점선을 표시해줘서 편했습니다.
(하지만 다른 기능은..말잇못.
3. 논리, 물리 ERD 단어 입력
이번 프로젝트에서 가장 노가다 작업이 아니었나 싶습니다.
일단 논리 ERD와 물리 ERD의 쉽게 설명해보자면 논리 ERD는 테이블명과 컬럼명이 한글로 표시되고, 물리 ERD는 모두 영어로 표시됩니다.
논리 ERD를 만들 때는 쉽습니다. 저희가 ERD를 만들 때 처음부터 한글로 입력하기 때문입니다. 테이블을 만들고 컬럼도 다 입력하고 PK도 설정하고 데이터타입도 입력하고 테이블 간의 관계선도 설정해주면 여러분은 논리 ERD는 다 만들었다고 생각하시면 됩니다! (와아 짱 쉽다
하지만 물리 ERD는 입력했던 한글을 다 영어로 다시 입력해줘야 합니다. 테이블 수와 컬럼 수가 적으면 수기로 다 작성할 수 있지만 실무에서 다루는 DB에는 무수히 많은 테이블과 컬럼들이 있을 겁니다.
네, 저희는 일일이 수기로 다 작성할 수 없습니다.
그렇다면 우리는 어떻게 해야 할까요?
다 방법이 있습니다. 바로 표준사전정의서를 이용하는 겁니다! 표준사전정의서를 토대로 nsm 파일을 만들어 이를 ERD에 적용시키는 겁니다.
표준사전정의서는 용어, 단어, 도메인을 입력한 자료로 각각에는 한글이름과 영어이름 데이터타입, 설명 등이 들어가 있습니다. 바로 논리 ERD에 들어가 있는 한글 컬럼명이 표준사전정의서 들어가 있다면 이 정의서에 설정되어있는 영어로 물리 ERD가 바뀌는 것이죠.
예를 들어 우리는 '성분명'이라는 컬럼을 가지고 있습니다. 표준사전정의서에 성분명이 INGR_NM으로 들어가 있다면
물리로 바꿀 경우 자동으로 INGR_NM으로 바뀌는 것입니다.
하지만, 표준사전정의서에 없는 컬럼들은 어떻게 될까요?
물리로 바꿔도 표준사전정의서에 없기 때문에 한글로 표시되어있습니다. 물리 ERD는 모두 영어로 표시되어야 합니다. 한글로 표시되어 있으면 안 됩니다.
그렇다면 우리는 어떻게 해야 할까요?
표준사전정의서에 해당 용어를 설정해줘야 합니다.
| 순번 | 용어 | 영문명 | 데이터타입 | 뜻 |
| 1 | 물품관리번호 | MNF_NO | VARCHAR(50) | 만들어진 제품을 관리하는 번호. |
이런 식으로 말이죠.
하지만 여기서 끝이 아닙니다. 모든 용어는 단어에서부터 나와야 하거든요.
예를 들어 '수거검사코드'라는 컬럼이 있습니다. 그렇다면 용어에 수거검사코드를 추가해줘야 합니다. 하지만 단어에 검사와 코드는 가지고 있지만 수거라는 단어는 없습니다. 이 경우 수거를 단어에 추가해줘야 하는 겁니다.
이 작업을 끝냈으면 다시 nsm 파일을 업데이트하고, 업데이트된 nsm 파일을 적용시키면 영어로 바뀌어져 있는 것을 확인할 수 있을 겁니다.
4. 테이블 간 중복된 컬럼이 있으면 안된다.
네, 가장 머리 아팠습니다.
예를 들어, 품목 테이블에 품목명이 있고, 성분 테이블에도 품목명이 있습니다. 이 둘은 부모, 자식 간의 관계를 가지고 있습니다.
처음에 작업할 때는 이 주의사항을 모르고 작업해 다음과 같이 설정했습니다.
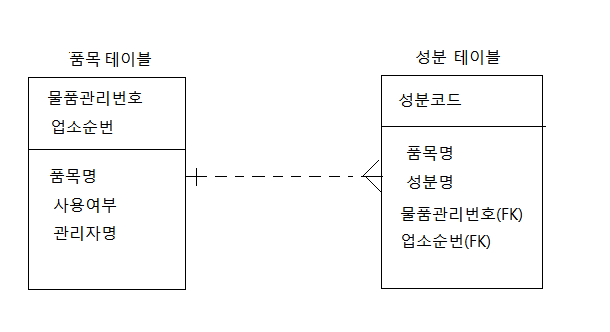
하지만 이렇게 연결되는 관계라면 부모 테이블인 품목 테이블에서 품목명을 가지고 올 수 있으니까 성분 테이블에는 품목명이 굳이 있어야 할 이유가 없습니다. 즉, 성분 테이블에서 품목명이라는 컬럼을 삭제해야 한다는 것이죠.
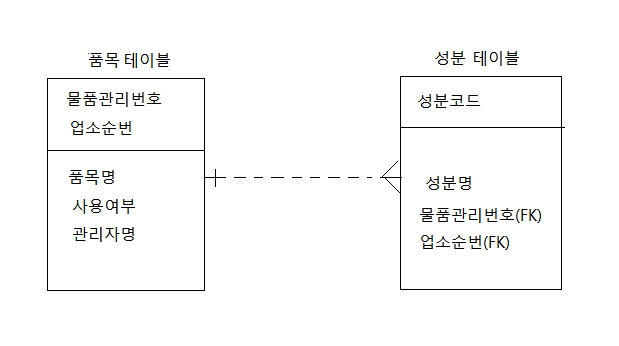
위 그림처럼 ERD 상에 표현할 때는 이렇게 표현해줘야 합니다.
만약에 가지고 올 수 없는 경우라면 어떻게 해야 할까요?
예를 들면 처분 테이블과 회수 테이블이 연결되어 있는데 처분 테이블의 품목명과 회수 테이블의 품목명이 다를 경우입니다. 이 때는 컬럼의 이름은 같지만 성질이 다릅니다. 처분 테이블의 품목명은 처분했을 때 그 제품의 이름이고, 회수 테이블의 품목명은 회수했을 때 그 제품의 이름이거든요.
이럴 때는 중복되면 안 되니까 둘 중의 하나는 이름을 바꿔줘야 합니다.
만약에 회수 테이블의 품목명을 회수품목명으로 바꿔줬다고 가정합시다. 그러면 저희는 회수품목명이 표준사전정의서에 들어 있나 봐야 합니다. 없으면 용어에 추가해줘야겠죠.. 하지만 단어에 회수가 없다면요. 그러면 단어도 추가해줘야 합니다..
이렇게 작업이 끝난다면 얼마나 편할까요.
사실 품목 테이블과 처분 테이블, 회수 테이블은 이어져 있습니다. 그렇다면 품목 테이블에서 품목명을 가져와도 되겠죠. 이를 늦게 발견했다면 다 용어, 단어 추가해준 노력들이 물거품이 되어 눈물을 머금고 처분 테이블과 회수 테이블의 품목명을 삭제해야 할 것입니다.
하지만 품목 테이블과 처분 테이블이 안 이어져 있다면?
그렇다면 품목명이 또다시 겹쳐버립니다. 그렇다면 둘 중에 하나를 또 바꿔줘야겠죠? 아마 처분 테이블의 품목명을 바꾸는 게 편할 겁니다. 처분품목명으로 바꾸는 게 제일 단순하고 빠르게 바꿀 수 있는 방법이니까요.
우리는 여러 개의 테이블들을 가지고 있습니다. 적게는 수십 개 많게는 몇 백개의 테이블들이요. 그렇다면... 머리 터져요. 계속 추가하고 제거하고 관계 살펴보고 무한의 굴레가 될 겁니다..
다시 정리하자면,
1. 테이블 간 중복되는 컬럼이 있는지 살핀다.
2. 중복이 된다면 같은 컬럼인지 확인하고 자식 테이블의 중복 컬럼은 지운다.
3. 만약 같은 컬럼이 아니라면 중복되지 않게 둘 중 하나의 컬럼명을 바꾼다.
4. 바꾼 컬럼명이 용어로 등록되어 있지 않다면 등록시킨다.
5. 물리 ERD가 완성될 때까지 1~4번을 반복한다.
라고 정리해볼 수 있겠습니다.
이 외에도 주의하면서 작업해야할 사항들이 몇몇 더 있지만 기회가 되면 다음 글에 정리해보도록 하겠습니다.
프로젝트 회고글 같기도 하지만 이번 프로젝트를 진행하면서 DB를 다루는 사람들이 굉장히 존경스러웠습니다.
아직도 갈길이 먼 주니어 데분가는 열심히 또 달려보겠습니다.
'데이터분석 공부하기' 카테고리의 다른 글
| 선형판별분석 LDA 이해하기 (0) | 2022.09.18 |
|---|---|
| 클러스터형 인덱스와 보조 인덱스 (0) | 2022.08.21 |
| 로지스틱 회귀 (0) | 2022.03.21 |
| 다항 회귀 (0) | 2022.03.17 |
| 선형 회귀 (0) | 2022.03.17 |



댓글